动手深度学习note-7(BERT-来自Transformer的双向编解码器表示)
手撕BERT——从注意力开始
前言:
作为一名初学者,在学习d2l的课程时,整个注意力机制这一部分虽然有代码讲解,但对于自己来说理解难度实在太大,根据课程的内容,多方查阅相关资料,历经九九八十一难,总算是磕磕绊绊的勉强看懂了代码。
本文的代码对d2l中的实现进行了解释,并对部分令初学者难以理解的代码从一个初学者的角度做了修改,修改不求优化代码执行效率(没那个水平),只求能够以更明了的方式去理解模型的原理
概述:
在BERT之前,在计算机视觉领域已经有在ImageNet上训练的通用模型,通过针对具体的下游任务,修改少量模型参数在较少的数据集上进行训练已经取得了良好的效果。而在NLP领域,还没有这样的通用模型,BERT的目的就是在大量的数据上训练一个通用模型,来通过微调来完成各种下游任务。
为什么能够进行预训练(PreTraining)
按照自己的理解:首先,神经网络的本质上是一个特征提取器,下游的具体任务不同只是如何利用这些特征的问题。我们在整个机器学习或者深度学习中,已经进行了同分布假设,就假定训练样本的数据按照某个相同的分布规律,这样,不同样本在同一位置的数值表示可以共用同一套参数。现在,我们如果在足够大量的数据上有足够多的参数,这样训练的结果就认为学习到了整个大样本的分布规律,提取到了足够多的特征,从而最后获取的特征能够满足不同的任务
类比与让人来识别一个东西是什么,对应的输入经过预训练模型的输出每一个通道就类似于告诉你不同的信息,比如第一个通道是告诉你颜色,第二个通道告诉形状,以此类推,如果这样的信息有足够多,那么,就能有较高的把握判断出要识别的是什么。
基于这样的认识,可以这样认为
- 在CV任务中,我们认为无论进行什么物体的识别,物体的最主要的特征就只包含输出的通道数这么多个,这些通道数的信息又是之前的各种层在某一方面提取的信息的总和,这样就完成了从图片到特征的压缩,最后如果是分类任务,其实就是基于这些特征的再压缩,得到一个
最抽象的结果,而这个结果就是需要的输出- 同理,在NLP领域中,对于每一个词,经过预训练模型,同样能够提取到足够的每个词本身以及与其他词的关系的足够多的特征,这些提取到的特征我们认为在最好的情况下是捕捉到了整个句子的所有特征以及内在的语义关系,这些特征就可以拿来完成下游具体的文本任务
模型推导与实现
导入依赖包:
1 | |
BERT充分借鉴了Transformer的架构,其实其本质就是Transformer的编码器部分,只不过在具体的细节上有略微不同。
BERT的目的是做通用的NLP模型,其目的不再是文本翻译,因此可以认为只有编码器来提取信息而不需要解码器输出。
BERT的数据集是不需要经过标注处理的文本,通过预处理读取一对句子对,通过两个任务(
Predict Masked Tokens和Predict Next Sentence)实现自监督学习,由于不需要进行标注,所以可以在非常大量的数据集上进行训练。
Transformer架构
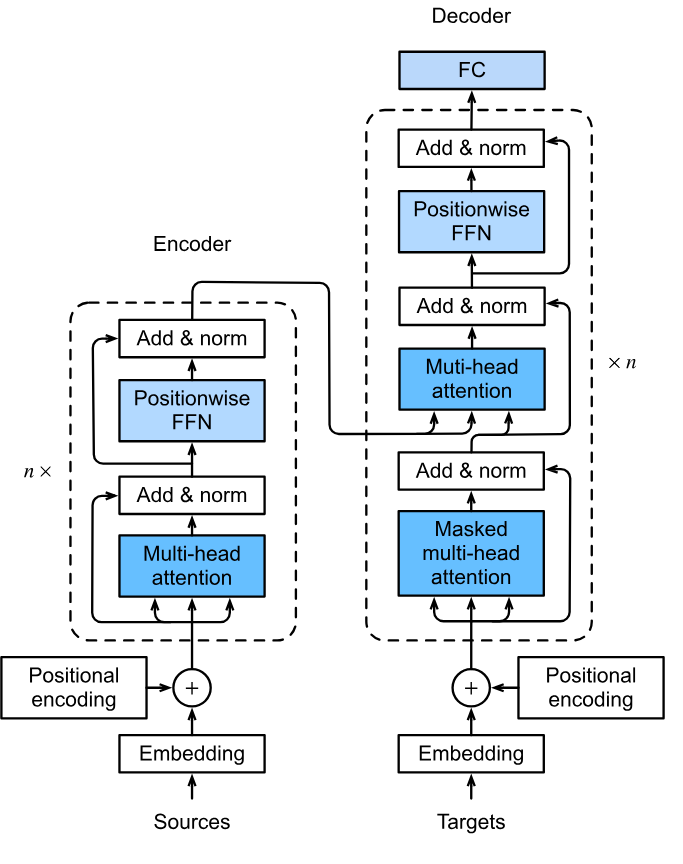
编解码器架构
从整体上看,Transformer使用了编-解码器架构,编码器负责提取信息,解码器负责输出。BERT中没有输出标签,所以自然也没有解码器。
注意力机制(Attention)
这里说一种我最认可的理解:
首先,对于注意力机制的意义应该通过类比人来观察物体来理解
无意识的观察
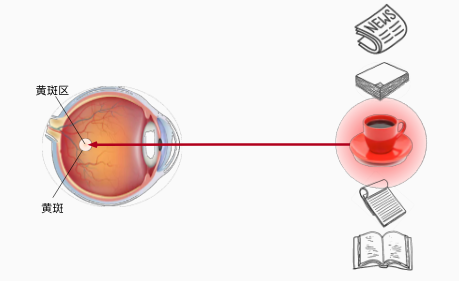
回忆之前的全连接和卷积,就是类似于人的一种观察,这样观察的结果最好的情况下是有所有的东西的,但是,正如人在无意识的观察的时候不可能能关注到所有的细节,神经网络在做相同的事情时也无法捕捉到所有的信息,捕捉信息的侧重是不同的,这个侧重可能是由物体的特定的形状、颜色是否鲜艳等来特定的特征来决定,通常来说,和人观察一样,卷积和全连接操作通常对颜色较为鲜艳的物体更加敏感。
因此,不难发现,全依靠这种方式不能精准且高效的捕捉到我需要的信息
例如:
在这张图片中,如果我的问题是这是一个什么场景,这样提取到的关于
坑的信息就不重要了,虽然后续有全连接层进行选择,但如果这个坑更大可能就会影响模型的判断。如果让问一个人这是什么场景:
- 这个人的操作大概是先看清了这是条街,然后才会注意到坑
同样的图片,如果询问这条街道有什么不同:
- 回答时大概率会立刻注意到有个坑在路中
因此,在有了询问的时候,人看东西就有了目标,会自觉的按着目标去查找有用的信息,这样便有了第二种观察方式。

有意识的观察
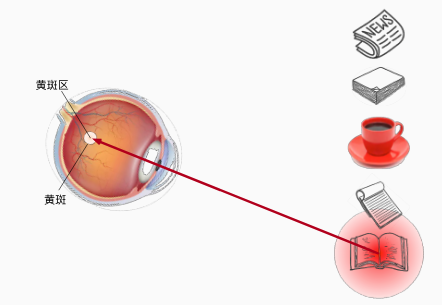
同样的场景,当明确我要看书的时候,我会去找书而不是杯子,这里捕捉的信息杯子的信息对我来说就不重要了。
为了模拟这种过程,使用了查询
(query)来模拟这种有意识
注意力汇聚
但是,要理解注意力机制具体是怎么算出来的又不能按照注意力来理解,应该按照全局查找\(\rightarrow\)计算权重\(\rightarrow\)加权求和来理解
例:
key value 张三 [1, 2, 0] 18 张三 [1, 2, 0] 20 李四 [0, 0 ,2] 22 张伟 [1, 4, 0] 19 全局查找
如果假设
key[0]==1表示姓张,那么要计算平均年龄就可以用
2
3
4dot([1, 0, 0], [1, 2, 0]) = 1
dot([1, 0, 0], [1, 2, 0]) = 1
dot([1, 0, 0], [0, 0, 2]) = 0
dot([1, 0, 0], [1, 4, 0]) = 1这里的计算结果是1就可以理解为对于查询
query(姓张)对这个key的注意力为1,也就是满足匹配信息计算权重
然后对输出
[1, 1, 0, 1]进行\(softmax\)操作,得到的是对每个key的注意力权重
softmax([1, 1, 0, 1]) = [1/3, 1/3, 0, 1/3]计算结果
[1/3, 1/3, 0, 1/3],有三个值为\(\frac{1}{3}\),含义为这三个key对query相同权重(因为都姓张),值为0(因为不姓张)则表示这个key对query的注意力为0加权求和
dot([1/3, 1/3, 0, 1/3], [18, 20, 22, 19]) = 19分别乘上数值
value就计算出所有姓张的平均年龄
用数学语言来表示:
query: \(\mathbf{q}\)key: \(\mathbf{k}\)value: \(\mathbf{v}\)将
[1/3, 1/3, 0, 1/3]称作注意力分数,用 \(\alpha(\mathbf{q},\mathbf{k_i})\) 表示,用\(a\)来表示注意力评分函数,可以得到: \[ \alpha(\mathbf{q},\mathbf{k_i})=softmax(a(\mathbf{q},\mathbf{k_i}))=\frac{e^{a(\mathbf{q},\mathbf{k_i})}}{\sum_{j=1}^{m}e^{a(\mathbf{q},\mathbf{k_j})}} \] 得到计算结果的过程称作注意力汇聚,用 \(f(\mathbf{q}, (\mathbf{k_1}\mathbf{v_1}), (\mathbf{k_2}\mathbf{v_2}), ... (\mathbf{k_n}\mathbf{v_n}))\) 来表示注意力汇聚函数 \[ f(\mathbf{q}, (\mathbf{k_1}\mathbf{v_1}), (\mathbf{k_2}\mathbf{v_2}), ... (\mathbf{k_m}\mathbf{v_m}))=\sum_{i=1}^{n}\alpha(\mathbf{q},\mathbf{k_i})\mathbf{v_i}=\sum_{i=1}^{n}\frac{e^{a(\mathbf{q},\mathbf{k_i})}}{\sum_{j=1}^{m}e^{a(\mathbf{q},\mathbf{k_j})}}\mathbf{v_i} \]
自注意力(Self-Attention)
如果现在将所有的query,key,value都用一个输入X来表示,有趣的事情发生了:
注意力评分函数的输出也
注意力评分函数
放缩点积注意力
(Transformer和BERT使用的)
计算公式: \[
a=\frac{\mathbf{Q}\mathbf{K}^{\mathbf{T}}}{\sqrt{d}}
\] 注意力分数: \[
\alpha(\mathbf{q},\mathbf{k_i})=softmax(a(\mathbf{q},\mathbf{k_i}))=softmax(\frac{\mathbf{Q}\mathbf{K}^{\mathbf{T}}}{\sqrt{d}})
\] 这种注意力需要\(\mathbf{Q}\),\(\mathbf{K}\)具有相同的嵌入维度d:
即:
参数 形状 \(\mathbf{Q}\) (batch_size x n x d) \(\mathbf{K}\) (batch_size x m x d) \(\mathbf{Q}\mathbf{K}^{\mathbf{T}}\) (batch_size x n x m)
即每一个查询字符对每一个K中的字符的注意力
为什么要除以\(\sqrt{d}\),这里从实际的效果来演示,从数学的角度推导参见数学推导。
首先,建立一个基本的认识,\(softmax\)将输入置为\((0, 1)\)之间的一个数,输入数值越大越接近1,例如:
2
3
4# 生成一组演示样本
Q = torch.randn((1,2,4))
K = torch.randn((1,2,4))
score = torch.bmm(Q, K.transpose(1,2))
2
3# 输出:
tensor([[[-1.2134, -0.7983],
[-6.5540, 0.6934]]])不使用 \(\sqrt{d}\) 放缩:
2# softmax
torch.nn.functional.softmax(score, dim=-1)
2
3# 输出
tensor([[[3.9769e-01, 6.0231e-01],
[7.1156e-04, 9.9929e-01]]])可以看到,数值相对较大的\(softmax\)几乎将其值置为了1,相对小的则几乎为零,而且这里只经过了一次操作,而这样的块有许多个,所以理论上这样的效果还会产生累加,因而,最终的结果可能是某些非常显著的特征被置为1,其他被置为0,这样计算梯度的时候梯度会变得非常小甚至梯度消失,导致这部分参数很难更新。
引入\(\sqrt{d}\)的缩放
2
3# softmax with sqrt(d)
import math
torch.nn.functional.softmax(score/math.sqrt(4), dim=-1) # 4: Q or K shape[-1] -> d
2
3# 输出
tensor([[[0.4483, 0.5517],
[0.0260, 0.9740]]])同样的数值,这样计算的结果明显更加合理,没有出现极度靠近1或0的情况
放缩点积注意力代码实现
掩码\(softamx\)模块
实现这部分代码,只需要将公式输入便可,但是,输入的不同样本要求字数相同即num_qkv相同,然而现实中输入的句子不可能每个句子的字数相同,因而在实际中使用的填充Padding。
在进行注意力分数计算的时候,明显的,对于查询query对这部分key的字符的注意力分数应该为0,也就是经过\(softmax\)后对应位置的输出为0,所以,在这部分代码的实现中,必须先来定义一个\(softmax\)函数——带掩码的\(softmax\)来完成。
1 | |
在数据预处理的时候会填充完后会记录下开始填充的位置,然后生成一个和填充相同形状的矩阵,矩阵的值为截断位置的索引。
masked_softmax函数的原理是将掩蔽的位置的值设置为一个非常小的数,这样在\(softmax\)的时候这个数的值就能变为0。
为了找出哪些位置被Padding,这里又构造了一个辅助函数sequence_mask:
1 | |
这是整个Transformer乃至整个BERT实现中非常难以理解的一部分代码,使用到了广播机制。
逐行解读:
首先要理解输入X:
在上一个函数中X表示\(\frac{\mathbf{Q}\mathbf{K}^{\mathbf{T}}}{\sqrt{d}}\)的值,形状为
(batch_size, n, m)注:在实际中,
n和m的值相同,都表示填充后的句子长度在将参数
X传入sequence_mask函数的时候对X进行了reshape:X.reshape(-1, X_shape[-1])因此,实际上函数输入
X的形状为(batch_size x n, m),也就是将多个维度按顺序堆叠到了一起
第一行maxlen拿到了X的第1为也就是m——key的长度
1 | |
首先,明确两个基本点:
mask本质上是比较运算,返回的数值应该是
TrueorFalse此处
valid_len的形状应该与X.size(0)相同(具体valid_len形状的变化会在介绍后续函数时说明)以一个直观的例子说明:
假设
maxlen=5:1
2
3
4sequence = torch.arange((5), dtype=torch.float32)
# 输出:
tensor([0., 1., 2., 3., 4.])假设
valid_len的值为2,即从索引2位置开始就不需要了如果
batch_size=1,那么valid_len应该为:1
tensor([2., 2., 2., 2., 2.])需要被
mask的X的形状应该为:(5, 5)
基于这个示例:
mask这里的X的思路应该是:每一行,从索引2位置开始就不需要了,将值设为-1e6正常的实现方式:
将
sequence按行复制valid_len.size(0)=5份 # 按多少句话复制1
sequence = sequence.repeat(5,1)1
2
3
4
5
6# 输出:
tensor([[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.],
[0., 1., 2., 3., 4.]])将
valid_len转置,然后按列复制sequence.size(1)=5份 # 按对多少个字的注意力复制1
valid_len.unsqueeze(0).transpose(0,1).repeat(1,5)1
2
3
4
5
6# 输出:
tensor([[2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2.]])然后比较
sequence和valid_len1
sequence < valid_len1
2
3
4
5
6输出:
tensor([[ True, True, False, False, False],
[ True, True, False, False, False],
[ True, True, False, False, False],
[ True, True, False, False, False],
[ True, True, False, False, False]])可以观察到,每一句话,从索引2开始就被标记为False了,这样,我们成功的根据
valid_len筛选出了被Padding的字符
其实,这一个过程能够通过
PyTorch的广播机制实现,当比较的两个矩阵的形状不同,广播机制能够自动广播到相同的维度。所以,这个过程可以这样实现
1
2
3
4
5
6
7
8
9
10
11
12sequence = torch.arange((5), dtype=torch.float32)
valid_len = torch.tensor([2,2,2,2,2], dtype=torch.float32)
# sequence能够按行广播,需要在第0维添加一个维度
sequence = sequence[None,:]
# 或: sequence = sequence.unsqueeze(0)
# valid_len能够按列广播,需要在第1维,添加一个维度
valid_len = valid_len[:, None]
# 或: valid_len = valid_len.unsqueeze(1)
sequence < valid_len得到相同的结果:
1
2
3
4
5tensor([[ True, True, False, False, False],
[ True, True, False, False, False],
[ True, True, False, False, False],
[ True, True, False, False, False],
[ True, True, False, False, False]])有了筛选的结果,将这
boolean的矩阵保存为mask,mash的形状与需要掩蔽的X相同,于是可以这样掩蔽:1
X[~mask] = value这里先将mask的元素取反,这样需要
mask的位置就为True,因而可以索引出对应X中的值,将这个值设置为value,通常为一个非常小的数
实现放缩点积注意力
有了实现好的掩码注意力模块,正式实现放缩点积注意力就非常容易了
实现了一个
DotProductAttention类继承自nn.Module,定义一个初始化函数和前向传播函数
1 | |
另外:还有一种常用的注意力叫做加性注意力(Additive Attention)在d2l课程中提到
在加性注意力中,\(\mathbf{k}\)和\(\mathbf{q}\)不再要求有相同的嵌入维度d,而是由一个单层的全连接层映射到一个相同的维度
计算公式为: \[ a(\mathbf{q},\mathbf{k})=\mathbf{w}_{v}^{\mathbf{T}}tanh(\mathbf{W}_{\mathbf{q}}\mathbf{q}+\mathbf{W}_{\mathbf{k}}\mathbf{k}) \] 理论上效果更好,但据说在实际中差别不大
多头注意力
理解多头注意力
现在,有了基本的注意力模块,终于可以来实现多头注意力了
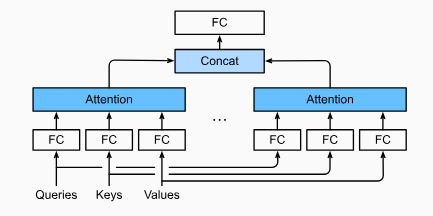
其实本质上就是一份q,k,v复制成多份,然后每一个”头“的输入q,k,v是原本的q,k,v乘上一个可学习的参数矩阵\(\mathbf{W}_{\mathbf{q,k,v}}\),这部分最难理解也是最奇怪的是在具体实现的时候将多个”头“拼接在一起计算,计算的时候做的其实又类似于一个非常大的”单头注意力“。
而所谓的多个头并没有通过复制多份加上多个参数矩阵来完成,而是通过一个参数矩阵映射到num_hiddens维,将num_hiddens维分成num_heads块,每一块我们认为是一个头。然后通过矩阵的形状变换,让不同的头在batch_size这个维度拼接。
同时可以认为构造出的不同的头可以用来分别提取不同类型的输入信息,类似于卷积不同通道的效果。
多头注意力代码实现
为了让”多个头“通过”一个头“来计算,我们必须先来定义两个辅助函数来完成矩阵形状的变换。
1 | |
1 | |
然后连接这些函数,实现Multi_Atttention类
1 | |
其中由于多个头其实是按batch_size这个维进行拼接的,因此valid_lens也需要复制num_hiddens份。
Add&Norm层
其实到目前位置,整个解码器的核心已经了解结束了,接下来是一些附加的模块
这一部分就是借鉴了ResNet的思想,使用残差连接来解决梯度消失问题。
假设MultiHeadAttention的作用称作函数\(f\),输入为\(\mathbf{X}\),其数学表达为: \[
Normlization(f(x)+x)
\] 特别的,在Transformer中使用的\(Normlization\)方法是\(LayerNormlization\)而不是ResNet中使用的\(BatchNormlization\)。
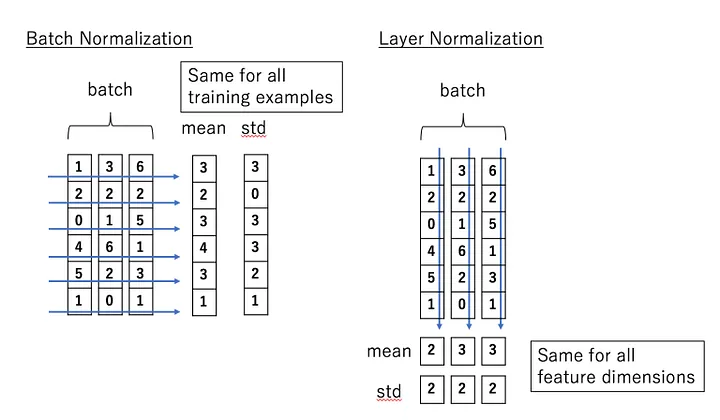
一种简单的理解:
图片采用
BatchNorm是因为我们认为在图片读取的每一个小批量的信息中不同样本的同一个特征维的数值分布应该大致相同,比如都是纹理信息的表示而在Transformer中,使用
LayerNorm是因为我们认为是同一个样本的所有特征维的数值分布应该是大致相同的,而不同样本的相同特征维关系不大,就比如不同句子在相同的位置的词可能词性都不相同,这样他们的特征维也应该是不同的,因此,还采用BatchNorm是没有意义的,因为应用Norm的数据本身就没有特定的关系
代码实现
1 | |
基于位置的前馈网络(FFN层)
其实就是两个全连接层,第一个全连接层将样本维从num_hiddens映射到ffn_hiddens,第二个全连接层又将样本维从ffn_hiddens映射回num_hiddens。FFN层使用ReLu作为激活函数。
代码实现
1 | |
嵌入层与位置编码
这两部分在BERT中有不一样的实现,这里制作基本的介绍。
在嵌入层中,模型的输入的字符是单个的对应到字典的索引值,嵌入层就是将词索引嵌入到有意义的词向量,嵌入的参数能够随着模型一起学习。注意,嵌入权重还多乘了一个\(\sqrt{d_{model}}\)。
位置编码是整个Transformer中最无厘头的一部分,选用的方法非常奇怪。位置编码使用相同形状的位置嵌入矩阵\(\mathbf{P}\),矩阵\(\mathbf{P}\)的值满足以下关系式:
偶数列: \[ P_{i,2j}=sin(\frac{i}{10000^{2j/d}}) \] 奇数列: \[ P_{i,2j+1}=cos(\frac{i}{10000^{2j/d}}) \]
实现一个Transformer Encoder
1 | |
BERT架构
从Transformer到BERT
BERT Encoder Block的形状与Transformer Encoder Block的主体结构相同,因此可以直接复用BERT位置编码通过构建随机初始化的参数矩阵通过学习得到- 由于
BERT的输入不是单个的句子而是句子对,为了区分是前一个句子还是后一个句子,引入了段落编码
实现BERTEncoder
1 | |
自监督
BERT通过两个任务实现了自监督学习
任务一:预测被随机<mask>的词(完形填空)
- 本质上是一个多分类的任务
- 根据经过
BERTEncoder的输出,取出需要预测的词所在位置的特征表示(认为这个位置包含了词本身的性质以及与其他词关系的所有信息) - 将拿到的特征表示作为一个MLP的输入,分类到词表大小
代码实现:
1 | |
pred_position的形状为(batch_size, num_preds),每一个批量中的内容都是需要预测的词的位置索引
为了获取索引信息,这里使用了PyTorch的高级索引技巧
首先输入
X的形状为(batch_size, len_sentencePairs, num_hiddens),X包含了每个批量中每个字符的所有特征维度的信息现在,我们的目标是索引出每个批量需要预测的字符的所有特征维的信息
按照常规的思路,索引其中一个批量的一个字符的特征,会使用
X[(batch_index, one_predPos)]
例如:
X = torch.randn((2,4,5))
2
3
4
5
6
7
8
9tensor([[[-0.4885, 0.0097, -2.4597, 0.1487, 1.4205],
[ 0.9140, 0.5731, 1.1893, 0.8911, -1.8921],
[ 1.1929, -1.0281, 0.3921, -0.1117, -1.0114],
[-0.2798, -0.3925, -0.1226, -1.3862, -1.7268]],
[[ 0.1964, -0.3935, 1.1851, -0.8282, -1.5966],
[ 0.3506, -1.4511, 0.1969, 0.9041, 0.8857],
[ 1.4290, -0.1206, 1.9447, -1.9729, 0.6238],
[ 0.6116, -0.6430, -0.9231, 0.1967, -0.4616]]])
索引一个字符:
X[0, 1] # -> 第0个批量第1个字符的所有特征
tensor([ 0.9140, 0.5731, 1.1893, 0.8911, -1.8921])索引来自不同批量的多个字符
X[(0, 0, 1, 1), (0, 1, 2, 3)]
2
3
4tensor([[-0.4885, 0.0097, -2.4597, 0.1487, 1.4205],
[ 0.9140, 0.5731, 1.1893, 0.8911, -1.8921],
[ 1.4290, -0.1206, 1.9447, -1.9729, 0.6238],
[ 0.6116, -0.6430, -0.9231, 0.1967, -0.4616]])观察发现,每一个索引的效果其实等效于用来索引两个参数对应位置组合来实现的 ->输出的第0行就是X[(0, 0)]
根据这个提示,于是就有了一种思路:
既然索引的第一个参数用来指定批量索引,那么可以创建一个有arange一个batch_size长的张量,然后内部复制num_preds次
第二个元素是表示再每一个批量的位置,既然有了批量位置的定位,这部分就只用把pred_position展开成一个一维的张量
故有了这样的写法:
2batch_index = torch.repeat_interleave(torch.arange(0, batch_size), num_preds)
masked_X = X[batch_index, pred_position.reshape(-1)]
PyTorch的Linear操作的是最后一个维度,因此,h还需要将masked_X恢复成最初的形状
masked_X = torch.reshape(masked_X, (batch_size, num_preds, -1))
任务二:预测句子对中的句子第二个句子是不是相邻的句子
- 为了实现这个功能在句子对的开头添加了
<cls>的标签,这个标签专门用来进行是不是下一个句子的预测 - 预测的本质实际上是一个二分类问题,
<cls>标签跟随句子通过BERTEncoder后的输出可以认为包含了整个句子的信息
代码实现:
1 | |
实现BERTModel
这部分就是连接自监督的两个任务
1 | |
PreTraining
Dataset
要进行训练,先要构建一个用于
BERT训练的数据集,在d2l的Demo中,演示使用构建了一个简单的数据集,但这部分代码不容易理解,这部分尝试从一个初学者的角度尝试构建数据集
回忆数据集需要包含的内容
BERT的数据集是一个句子对,句子对会被填充或截断到相同的长度max_len,返回包含和句子对相同形状的valid_lens,需要返回用于segment编码的序列(第一个句子对应的字符的标签为0,第2个句子为1)- 数据集能够完成两个自监督任务
- 数据集中的句子对中的部分词被
Mask掉,返回的数据集需要包含Masked的句子对表示,Masked的词位置,Mask前的词索引表示 - 一部分句子的第二句被替换掉,为了能够预测句子对的开头需要加上
<cls>标签,每一句的末尾需要加上<seq>标签,返回是否有被替换的结果标签(包含True & False)以及替换后的句子对
- 数据集中的句子对中的部分词被
分析任务流的先后顺序可以这样实现:
从磁盘读取数据集\(\longrightarrow\)构建字典(包含可能用到的特殊标签)\(\longrightarrow\)生成句子对\(\longrightarrow\)添加开头、句末的标签\(\longrightarrow\)随机句子替换\(\longrightarrow\)随机字符掩蔽\(\longrightarrow\)根据字符生成索引\(\longrightarrow\)填充到max_len\(\longrightarrow\)生成用于segment编码的序列
代码实现
导入依赖包:
1 | |
读取数据集
下载wikitext2的训练数据集.parquet格式用于导入
1 | |
构建字典
在原版BERT中使用的是词根的方法,这里做简化处理
字典设置一个字符出现的最小频率(小于该频率的用<unk>表示减小字典大小),实现索引到字词idx_to_token和字词到索引token_to_idx两个方法
1 | |
生成随机替换掉的句子对
有50%的概率第二句话被替换为随机选取的句子
1 | |
随机掩蔽单词
有句子对长度,15%的单词被掩蔽
掩蔽有三种方法完成
- 80%概率将单词置为特殊标签
<mask>;- 10%概率随机选一个词替换;
- 10%概率保持不变
1 | |
生成每一段的数据集(数据样本的结构:数据集->段->句子)
1 | |
填充并生成索引
这里的填充不仅包括句子对的填充,由于句子对的长度不同,导致
mask的长度也不同,故也需要填充,而为了区分哪些是填充,哪些是真实的<mask>标签,引入了masked_weights(具体用法将在实现训练部分说明)
1 | |
构建数据集
使用PyTorch构建数据集采用实现torch.utils.data中的Dataset来实现
查看PyTorch中的Dataset部分的源码
1 | |
Dataset是一个抽象类,继承这个抽象类的时候必须实现__getitem__接口,这个接口接受输入为索引值,根据索引值返回对应批量的标签。- 此外
Dataset还实现了一个__add__方法,用来用来将两个数据集合并 - 从注释中可以知道,
Dataset搭配DataLoader使用
实现:
这里额外实现一个save方法,用来保存数据集,方便下次调用,Vocab将以JSON的格式保存
1 | |
1 | |
生成训练集
1 | |
训练
导入数据集:
导入单词表(从JSON)
1 | |
导入预处理的数据集(从pt)
1 | |
初始化
默认情况下,
nn.CrossEntropyLoss中的reduction参数的值为'mean',会对每个batch中每个预测样本的loss计算一个全局的平均值;但是,在此次任务中,对于
masked_tokens的预测使用到了填充,因此填充部分的损失应该不参与取均值;因此,这里手动指定
reduction='none',对每个batch的每个预测不做处理
1 | |
计算每一个step的损失
在生成
maked_tokens的数据集中引入了一个标记masked_weights,真实的预测位置标记为1,填充部分的标记为0,这里计算均值时使用所有loss的和去除以真实位置的数量
1 | |
训练BERT
1 | |
展示
这里只展示代码能够正常运行,实际上,在真实的BERT预训练与d2l课程中的Demo有较大的差距
| Model / Params | num_hiddens | ffn_hiddens | num_heads |
|---|---|---|---|
BERT base |
768 | 3072 | 12 |
BERT large |
1024 | 4096 | 16 |
此外,BERT中的激活函数用的是GeLu而不是ReLu
ReLu:\[ f(x) = max(0, x) \]
GeLu:\[ f(x) = x \cdot \Phi(x) \]\[ \Phi(x) = \frac{1}{\sqrt{2\pi}}\int_{-\infty}^{x} e^{-\frac{t^2}{2}} d \]
对比
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38import numpy as np
import matplotlib.pyplot as plt
# 定义 ReLU 函数
def relu(x):
return np.maximum(x, 0)
# 定义 GELU 函数
def gelu(x):
return x * 0.5 * (1.0 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * np.power(x, 3))))
# 生成 -3 ~ 3 的连续数字作为 x 坐标
x = np.linspace(-3, 3, 1000)
# 绘制图像
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
fig.suptitle('Comparison of ReLU and GELU Functions')
# 在子图 1 中绘制 ReLU 函数
ax1.plot(x, relu(x), label='ReLU', lw=2)
ax1.set_ylim([-0.5, 3])
ax1.axhline(y=0, color='k', lw=0.5)
ax1.axvline(x=0, color='k', lw=0.5)
ax1.set_xlabel('x')
ax1.set_ylabel('ReLU(x)')
ax1.legend()
# 在子图 2 中绘制 GELU 函数
ax2.plot(x, gelu(x), label='GELU', lw=2)
ax2.set_ylim([-0.5, 3])
ax2.axhline(y=0, color='k', lw=0.5)
ax2.axvline(x=0, color='k', lw=0.5)
ax2.set_xlabel('x')
ax2.set_ylabel('GELU(x)')
ax2.legend()
# 显示图形
plt.show()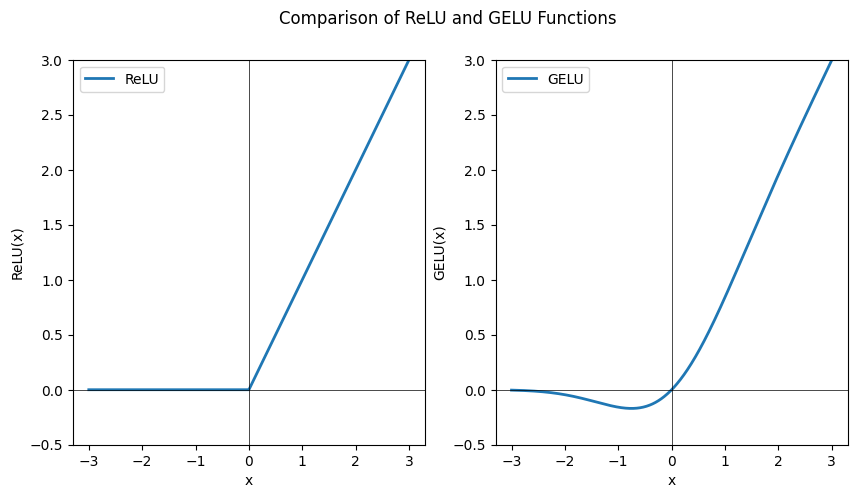
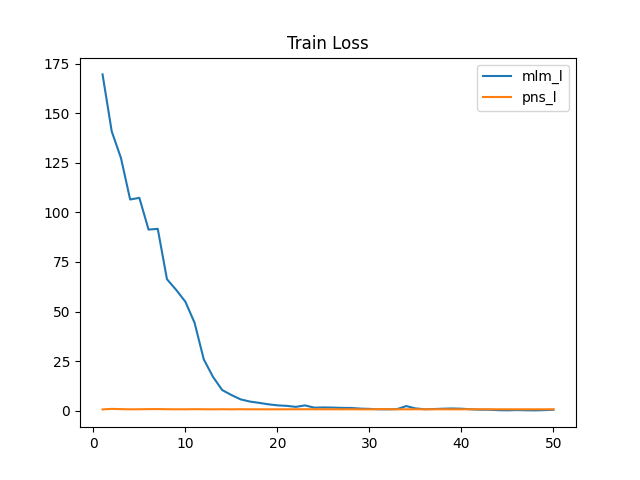
第一轮结束:
1 | |
按照上面的参数,50轮训练后
1 | |
关于预训练部分的代码汇总
数据集
1 | |
预训练
1 | |